
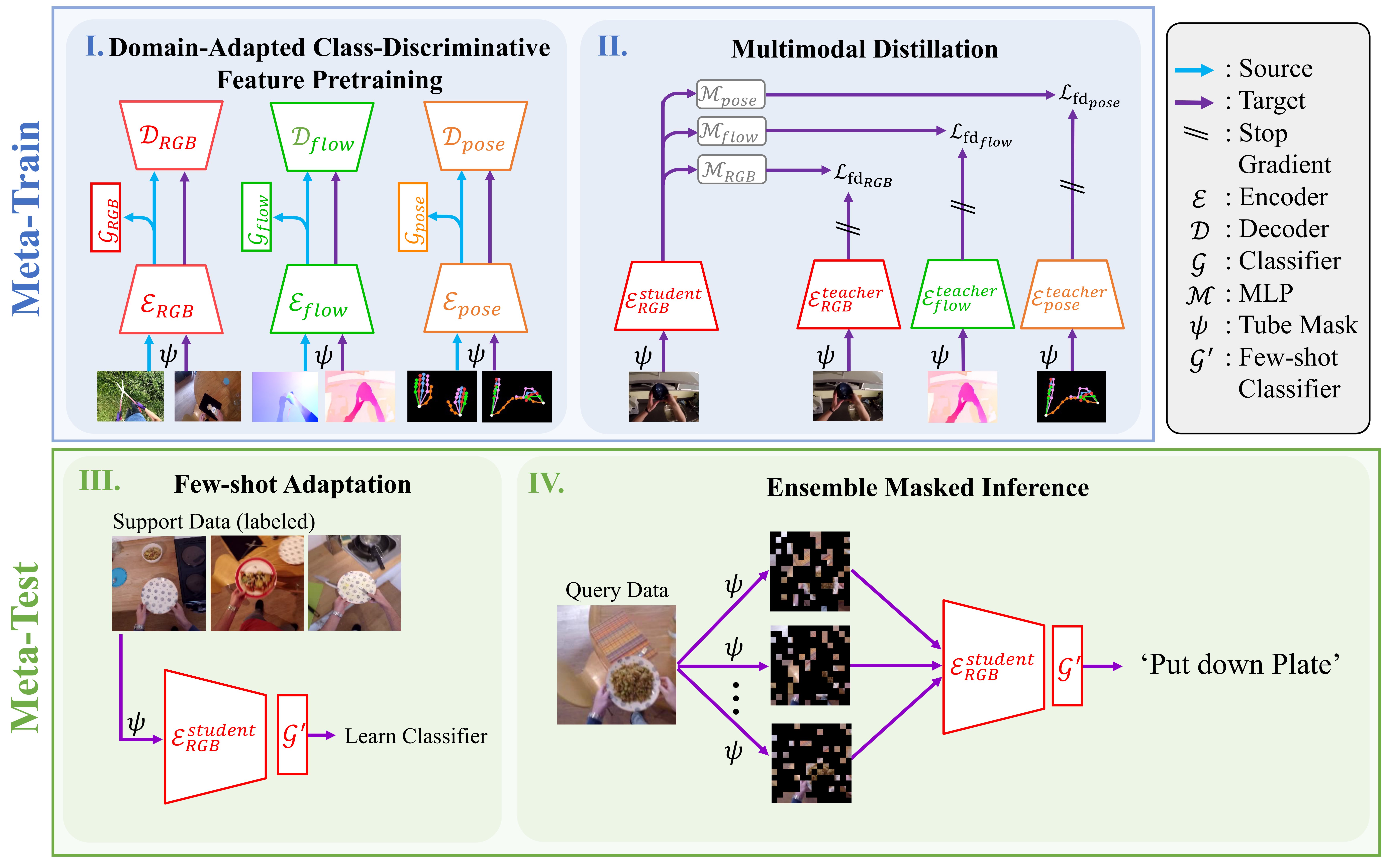
We address a novel cross-domain few-shot learning task (CD-FSL) with multimodal input and unlabeled target data for egocentric action recognition. This paper simultaneously tackles two critical chal-lenges associated with egocentric action recognition in CD-FSL settings:(1) the extreme domain gap in egocentric videos (e.g., daily life vs. indus-trial domain) and (2) the computational cost for real-world applications. We propose MM-CDFSL, a domain-adaptive and computationally effi-cient approach designed to enhance adaptability to the target domain and improve inference speed. To address the first challenge, we propose the incorporation of multimodal distillation into the student RGB model using teacher models. Each teacher model is trained independently on source and target data for its respective modality. Leveraging only un-labeled target data during multimodal distillation enhances the student model's adaptability to the target domain. We further introduce ensem-ble masked inference, a technique that reduces the number of input to-kens through masking. In this approach, ensemble prediction mitigates the performance degradation caused by masking, effectively address-ing the second issue. Our approach outperformed the state-of-the-art CD-FSL approaches with a substantial margin on multiple egocentric datasets, improving by an average of 6.12/6.10 points for 1-shot/5-shot settings while achieving 2.2 times faster inference speed.
@inproceedings{Hatano2024MMCDFSL,
author = {Hatano, Masashi and Hachiuma, Ryo and Fujii, Ryo and Saito, Hideo},
title = {Multimodal Cross-Domain Few-Shot Learning for Egocentric Action Recognition},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2024},
}